【Nat. Biomed. Eng.】重磅炸弹!医疗AI效率 暴增31.75% ,新模型MedMPT如何用 15万 张CT图像颠覆呼吸疾病诊疗!
✨文章标题:A vision–language pretrained transformer for versatile clinical respiratory disease applications ✉️作者:Hengrui Liang, Yuchen Guo, Jianxing He & Feng Xu 等 🔗链接:https://doi.org/10.1038/s41551-025-01544-z

从“痛点”到“突破”:AI如何打破医疗壁垒
想象一下,在全球范围内,包括慢性阻塞性肺病(COPD)、肺癌和呼吸道感染在内的肺部疾病,是导致人类发病和死亡的首要原因之一。对于这类复杂的胸部疾病,能否及时且准确地给出诊断和治疗方案,直接决定了患者的生存质量和医疗系统的运行效率。然而,现实的临床诊疗并非简单的一锤子买卖,它需要多学科专家(如呼吸科医生、放射科医生和肿瘤科医生)的通力合作,并综合分析多种模态的数据,包括医学影像、化验单、病史和药物关系等。
当前的人工智能(AI)模型虽然在某些单项任务上表现出色,例如基于CT影像的肺癌筛查或X光片报告生成,但它们普遍面临一个核心困境:缺乏一个统一的框架来处理临床流程中多样化、连续且复杂的多模态数据和任务。大多数现有模型往往局限于图像或文本单一模态,或者只关注临床工作流中的孤立环节,例如单纯的病灶分割或疾病诊断,这使得它们在真实临床转化中显得力不从心,可靠性也大打折扣。
正是基于这一行业痛点,清华大学等机构的研究团队推出了一个多模态预训练Transformer模型——MedMPT,一个专为呼吸系统医疗量身定制的AI模型。这个模型的诞生,不仅是为了解决一个孤立的技术问题,更是为了构建一个更通用、更贴近临床工作流的“通用目的AI”基础模型,从而真正提升医疗服务的效率和患者的治疗效果。MedMPT的出现,标志着医疗AI从“单项冠军”向“全能选手”迈出了关键一步。
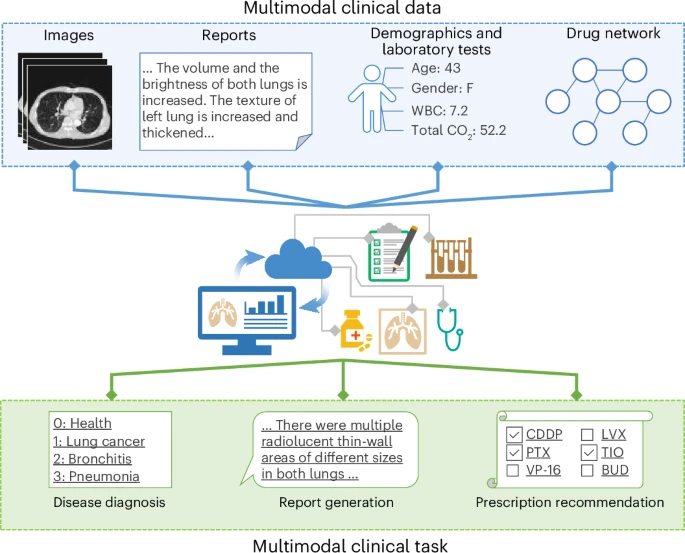
核心方法与技术细节解密:AI如何拥有“临床思维”
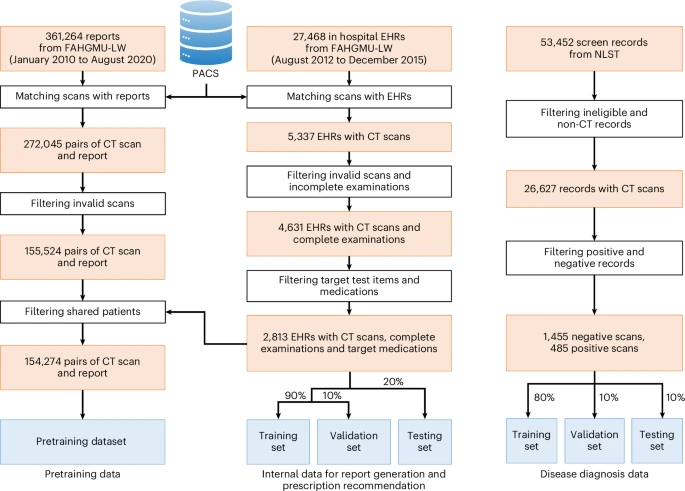
MedMPT之所以能够超越前辈,核心在于其以临床为导向的创新预训练策略和对多模态数据的深度整合能力。它不再是简单地将通用AI模型在医学数据上做“微调”,而是从零开始,在超过154,274对胸部CT扫描和放射科报告数据上进行自我监督学习。我们可以将其创新机制概括为“三维视觉整合”和“四重目标驱动”。
3D视觉:像放射科医生一样看CT
传统的AI模型在处理CT扫描时,往往将CT图像视为一系列独立的二维切片(2D slices),这就像让医生只看单张照片来判断病情,忽略了病灶在三维空间中的完整结构和上下文关系。而CT扫描本质上是一个多切片的立体数据。
MedMPT的创新点在于其视觉编码器引入了切片融合模块(Slice Fusion Module)和注意力机制。它不像其他模型那样只在二维图像上进行对比学习,而是将一系列连续的CT切片作为一个统一的整体来处理。这让模型能够捕捉切片内的细微特征(如结节、毛玻璃影),同时还能理解切片间的上下文关系,即病灶在整个肺部的全局分布和解剖学背景。这种机制使得AI拥有了全局和局部兼顾的“临床思维”,特别是在肺癌筛查或COVID-19严重程度分级这类需要整体评估的任务中,优势尤为明显。
四重目标:打造全能多模态大脑
为了让模型从海量未标记的医学数据中汲取“临床经验”,MedMPT采用了多任务预训练算法,同时优化了四个互补的目标,就像给模型设置了四项自我提升的挑战。
1. 模内对比学习(IIC):自寻其源的视觉逻辑
这一目标旨在训练模型捕捉CT图像自身内在的结构和上下文关系。MedMPT在切片级别和扫描级别两个尺度上进行对比学习。就好比让模型自己去分辨,同一病灶在不同角度下的切片(正样本)应该有相似的表达,而不同病人的切片(负样本)则应该被区分开。这确保了模型能学习到稳健的、具有临床意义的视觉特征。
2. 模间对比学习(ITC):图像与文本的语义对齐
这一环节是MedMPT多模态能力的核心。它将CT图像(视觉特征)与对应的放射科报告(文本描述)在共享的潜在空间中进行对齐。传统的模型可能将文本与单个2D切片对齐,但MedMPT则将报告与整个CT扫描的聚合特征进行对齐。这要求模型不仅要识别出图中的病灶,还要理解报告中详细、专业的语义信息,例如“磨玻璃影”和“网状影”在图像上具体对应哪个区域。这极大地增强了模型对全局临床上下文的理解。
3. 掩码图像重建(MIR):细节决定成败
由于医学影像中的关键异常往往微小且局部化,MIR被引入作为IIC的补充。就像给CT切片打上“马赛克”,然后让模型根据周围可见的像素来精确重建被遮挡的部分。这项任务迫使模型将注意力集中到局部细粒度的特征上,这对于在复杂解剖结构中识别微妙病变至关重要。
4. 跨模态生成(CMG):将视觉转化为专业语言
这是让MedMPT具备生成报告能力的关键。模型需要根据输入的CT图像特征,自动生成一份内容正确且描述完整的放射科报告。这项任务反过来又要求模型对图像内容有最全面、最透彻的理解,因为只有真正理解了图像中的所有细节,才能将其转化为专业、连贯的医学文本。
这四重目标共同作用,使得MedMPT从海量数据中习得的不再是孤立的模式匹配,而是整合了图像、文本和临床逻辑的“医学洞察力”。
数据背后的创新与颠覆性分析:效率与准确率的双重飞跃
MedMPT的性能在多项临床任务中实现了对现有最先进模型的压倒性超越,其颠覆性不仅体现在准确性上,更在于其展现出的临床实用性和资源效率。
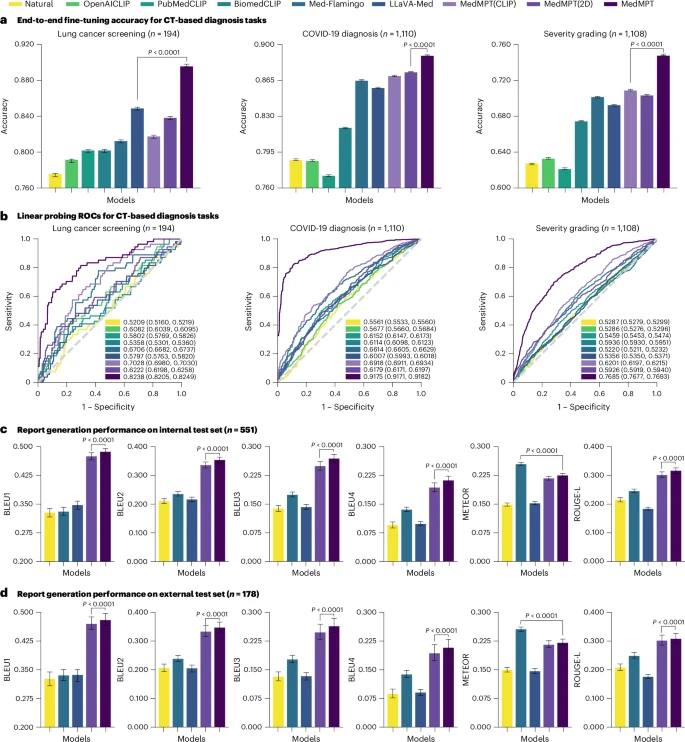
疾病诊断:平均准确率大幅领先
在CT影像疾病诊断任务中,MedMPT展现了卓越的通用性。
肺癌筛查: 在肺癌筛查任务中,MedMPT的准确率达到了0.8958,显著高于次优的LLaVA-Med的0.8490,AUROC(受试者工作特征曲线下面积,衡量分类性能的权威指标)更是达到了0.9269,P值小于0.0001,表明了统计学上的巨大优势。
COVID-19诊断与分级: 在COVID-19的诊断中,准确率为0.8892,AUROC为0.9391。即使是在难度更高的COVID-19严重程度分级任务中,MedMPT的准确率也达到了0.7477,相较于其他对比模型,性能提升超过了0.0388。
更值得注意的是参数效率的体现。在线性探针(Linear Probing)实验中,MedMPT仅调整了1,000-2,000个参数,其在肺癌筛查上的AUROC仍达到了0.8238。这一成绩媲美甚至超越了某些需要进行完全端到端微调、参数数量高达数千万甚至上亿(如OpenAICLIP的2亿多参数)的对比模型。这有力地证明了MedMPT在预训练阶段习得的特征表示质量极高,具备卓越的参数和数据效率。
报告生成:语义正确性的质变
报告生成是连接影像科和临床科室的关键环节,要求生成的报告具备全面性、专业性和流畅性。
在内部测试集上,MedMPT在主要的语言质量和语义正确性指标上均表现优异。例如,在常用的BLEU1指标上,MedMPT得分为0.4872,在ROUGE-L指标上得分为0.3169,全面超越了LLaVA-Med和Med-Flamingo等现有顶尖模型。它在语义准确性上的提升尤为显著,生成的报告更贴近人类放射科医生的专业水准,描述准确、用词专业。相比之下,对比模型生成的报告中则常出现不相关甚至捏造的内容(即“幻觉”)。
这背后的根本原因在于:大多数现有模型是作为生物医学聊天机器人训练的,预训练任务与临床报告生成这种需要详细描述和医学术语关联的专业任务存在错位。MedMPT的跨模态生成目标(CMG)则从预训练阶段就将任务目标与临床需求深度对齐,确保了其生成内容的临床有效性。
处方推荐:融合多模态数据的专家判断
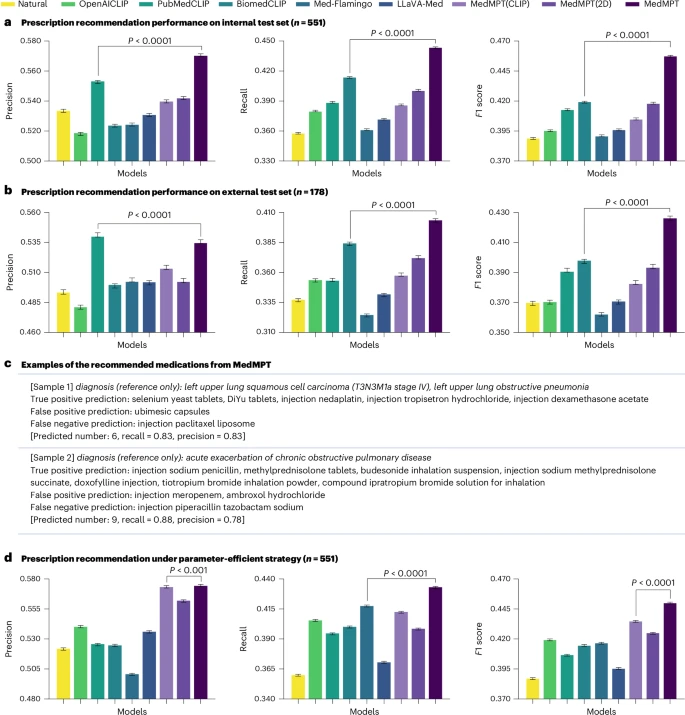
处方推荐是临床实践中最复杂、最需要多方面信息整合的任务之一,它要求AI具备综合判断患者CT影像、报告、化验结果以及药物相互作用的能力。
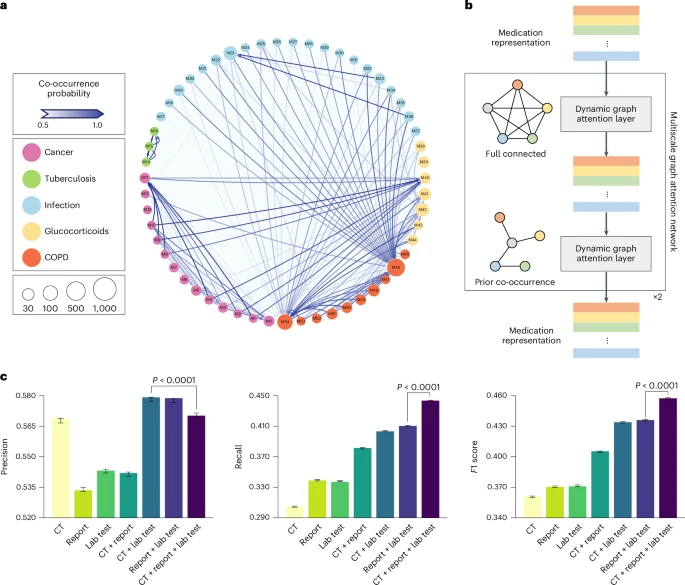
通过整合CT图像、放射科报告、人口统计信息和实验室测试结果这全套多模态数据,MedMPT在处方推荐任务上取得了F1分数0.4576的成绩。这一表现显著优于次优模型 BiomedCLIP的0.4195。
在对输入模态进行消融分析时,研究发现,加入任何单一模态都会持续提升性能。其中,仅使用CT图像、报告、化验单全部模态时,模型达到了最高的F1分数。这充分体现了多模态数据在复杂临床决策中不可或缺的整体性。
研究还引入了药物共现图,将被共同处方药物的关联知识建模到模型中。移除该图后,模型的F1分数会下降0.0081。这表明,AI不仅要从患者个体数据中学习,还要从海量真实世界处方数据中提取药物之间的临床关联这一集体知识,才能做出更合理、更像专家的处方建议。
人机协作:效率暴增31.75%的革命性突破
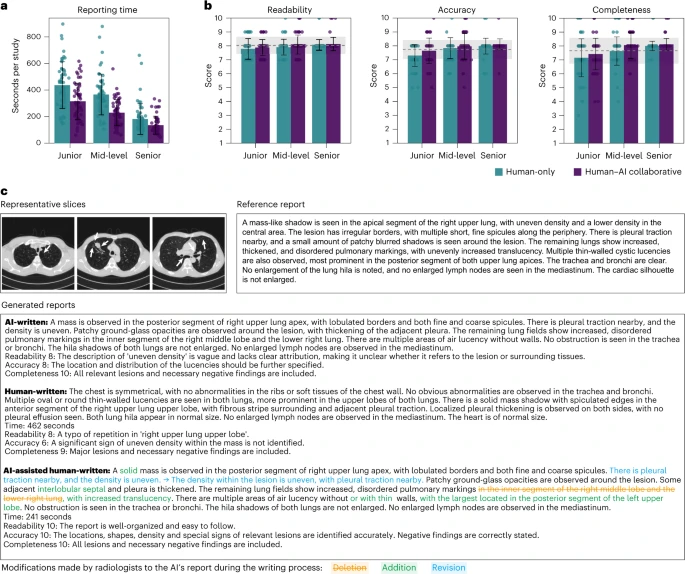
MedMPT最令人振奋的成果体现在人机协作环节,这也是其临床有效性的终极证明。在放射科报告生成流程中,MedMPT显著提高了工作效率和报告质量。
效率飞跃: 在放射科医生(包括初级、中级、高级)的协助下,平均报告完成时间从334.47秒减少到了228.28秒。这意味着平均效率提升了31.75%。其中,经验丰富的高级放射科医生获得的效率提升最大,达到了惊人的37.34%。这是因为他们能够更快地评估和整合AI生成的报告草稿,专注于临床内容的修正和提炼,而不是纠结于格式和基础描述。
质量提升: 报告质量评估(包括可读性、准确性和完整性)显示,MedMPT的协作有助于全面提升报告质量。对于初级放射科医生而言,人机协作将其报告的关键错误率从6%降低到了2%。同时,报告的临床接受率(所有三个维度评分均高于7,认为临床可用)也得到了普遍提高。MedMPT提供的AI报告草稿,如同一个强大的基线,帮助经验不足的医生识别并补全重要病灶和必要的阴性发现,从而缩小了不同经验水平医生之间的报告质量差距。
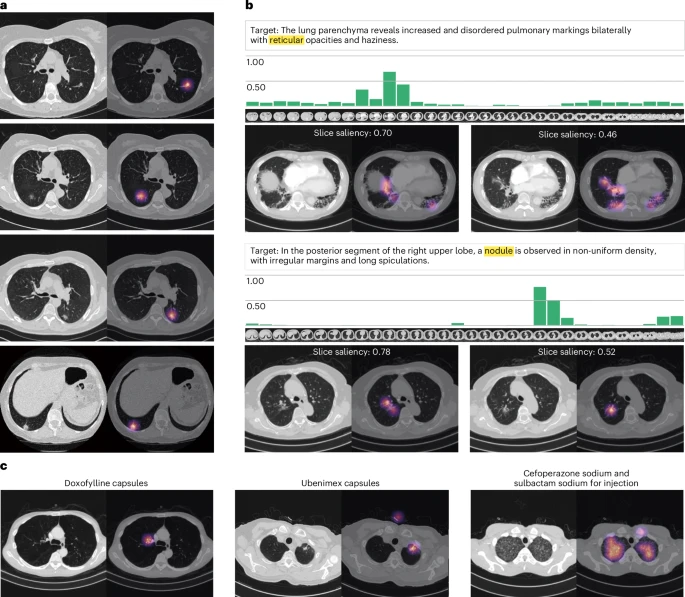
这些数据清晰地表明,MedMPT不是要取代人类医生,而是作为赋能工具,通过有效的人机协作,显著提升了临床工作流程的效率和质量。
应用展望、局限性与未来路线图
MedMPT的成功证明了多模态预训练模型在实现通用型临床AI上的巨大潜力。它的直接应用场景涵盖了辅助诊断、自动化报告生成、以及复杂治疗决策支持(如处方推荐)等多个呼吸系统疾病诊疗的关键环节。未来,它可以成为医院信息化系统中核心的临床决策支持引擎,减轻医生特别是初级医生的工作负担,让他们将更多精力投入到复杂的临床判断和人文关怀上。
然而,MedMPT也存在不容忽视的局限性。首先,目前的研究主要集中于呼吸系统疾病,并使用了胸部CT、放射科报告和实验室化验单等常用模态。MedMPT在其他疾病领域(如心脏、脑部)或其他模态数据(如病理切片、基因组数据)上的通用性尚未得到全面探索。
其次,研究中使用的内部和外部测试集在人口统计学和多样性上仍有待扩展,未来的工作需要纳入更广泛的地理和人群数据,以确保模型的鲁棒性和泛化能力。
展望未来,研究团队提出了清晰的路线图:
数据和任务的持续扩展: 不断收集更广泛、更均衡的多样化临床数据,将模型扩展到更多临床任务和模态。
更高级的训练策略: 探索多任务联合微调的进阶策略,例如混合专家模型(Mixture-of-Experts)和适配器策略(Adapter strategies),以更好地平衡模型在特定任务上的性能与在数据分布漂移下的通用性。
前瞻性临床验证: 从回顾性研究转向前瞻性评估,将MedMPT部署到真实的临床环境中进行测试,以更全面地评估其对患者预后和医疗系统的实际影响。
最后,最重要的一点是,研究团队强调:MedMPT始终应该被视为人类专家的“支持系统”,而非“替代品”。临床决策的最终权杖,永远掌握在具备专业判断、经验和对患者独特情况深刻理解的医护人员手中。AI的价值,在于增强而非取代人类的能力,二者结合,才能共同迈向更高效、更精确的医疗未来。